J’ai récupéré l’API GitHub le 18 mars 2026. J’ai parcouru des fils Reddit avec plus de 1 500 upvotes au total. J’ai vérifié les pages de tarification, les historiques de versions, les graphiques de commits.
Pas de vibes. Des données.
Les Chiffres
| LangChain | CrewAI | AutoGen | |
|---|---|---|---|
| Étoiles GitHub | 130,068 | 46,455 | 55,836 |
| Forks | 21,444 | 6,268 | 8,414 |
| Problèmes ouverts | 505 | 494 | 684 |
| Licence | MIT | MIT | CC-BY-4.0 |
| Dernière version stable | 17 mars 2026 | 18 mars 2026 (v1.11.0) | 30 septembre 2025 (v0.7.5) |
| Commits (4 dernières semaines) | 187 au total | 3 RC en 3 jours | Pratiquement zéro |
| Né | Oct 2022 | Oct 2023 | Août 2023 |
Source : API GitHub, récupérée le 18 mars 2026.
LangChain : 130K étoiles, 47 commits/semaine, trois ans et demi et toujours en accélération. Dites ce que vous voulez sur la DX — l’équipe livre.
CrewAI : 46K étoiles en deux ans et demi. Trois candidats de sortie en trois jours consécutifs avant que la v1.11.0 ne devienne stable. Énergie de petite équipe. Avançant rapidement, probablement en cassant des choses, mais au moins ils avancent.
AutoGen : c’est là que ça devient inconfortable. Dernière version stable ? Septembre 2025. Six mois de silence d’un projet soutenu par Microsoft. 684 problèmes ouverts qui s’accumulent. La réécriture v0.4 a divisé la communauté entre ceux qui utilisent l’ancienne API et ceux qui essaient de comprendre la nouvelle. Aucun des groupes ne semble heureux.
Montre-moi le Code
Assez parlé. Voici la même tâche — un agent de vérification météo — dans chaque cadre, plus le SDK standard. Portez votre propre jugement.
SDK OpenAI brut (pas de cadre)
from openai import OpenAI
import json
client = OpenAI()
def get_weather(city: str) -> str:
return f"72°F et ensoleillé à {city}" # votre appel API réel ici
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtenir la météo actuelle d'une ville",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}]
messages = [{"role": "user", "content": "Quelle est la météo à Tokyo ?"}]
response = client.chat.completions.create(
model="gpt-4o", messages=messages, tools=tools
)
# Gérer l'appel d'outil
tool_call = response.choices[0].message.tool_calls[0]
result = get_weather(json.loads(tool_call.function.arguments)["city"])
messages.append(response.choices[0].message)
messages.append({"role": "tool", "content": result, "tool_call_id": tool_call.id})
final = client.chat.completions.create(model="gpt-4o", messages=messages)
print(final.choices[0].message.content)
25 lignes. Zéro magie. Vous voyez chaque message entrer et sortir. Quand ça casse — et ça le fera — vous saurez exactement où regarder.
C’est de cela que parlait ce post Reddit à 685 upvotes quand il a dit « construisez le vôtre au brut ».
LangChain
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Obtenir la météo actuelle d'une ville."""
return f"72°F et ensoleillé à {city}"
agent = create_agent(
model="gpt-4o",
tools=[get_weather],
system_prompt="Vous êtes un assistant météo utile."
)
response = agent.invoke("Quelle est la météo à Tokyo ?")
print(response)
Propre. Court. Et complètement opaque. Que se passe-t-il à l’intérieur de agent.invoke() ? Boucle d’appel d’outil, formatage de message, logique de reprise, peut-être un peu de modélisation de prompt. Tout est géré pour vous. Merveilleux — jusqu’à 2 heures du matin quand votre agent commence à renvoyer des absurdités et que vous devez passer par cinq couches d’abstraction pour comprendre laquelle a mangé votre réponse d’outil.
La vraie valeur de LangChain n’est pas l’abstraction d’agent. Ce sont les 150+ intégrations (chaque magasin de vecteurs, chaque fournisseur LLM, chaque chargeur de documents auquel vous pouvez penser) et LangSmith, qui est vraiment le meilleur outil de débogage d’agent disponible en ce moment. Plus à ce sujet plus tard.
CrewAI
from crewai import Agent, Task, Crew
from crewai.tools import tool
@tool
def get_weather(city: str) -> str:
"""Obtenir la météo actuelle d'une ville."""
return f"72°F et ensoleillé à {city}"
weather_agent = Agent(
role="Reporter Météo",
goal="Fournir des informations météo précises",
backstory="Vous êtes un météorologiste qui donne des rapports météo concis.",
tools=[get_weather]
)
task = Task(
description="Quelle est la météo à Tokyo ?",
expected_output="Un bref rapport météo",
agent=weather_agent
)
crew = Crew(agents=[weather_agent], tasks=[task])
result = crew.kickoff()
print(result)
Plus de lignes, une ambiance totalement différente. Vous n’écrivez pas un script, vous réalisez un film. role, goal, backstory — l’agent a une courbe de personnage avant même d’avoir agi.
Pour vérifier la météo ? Une surcharge ridicule. Pour un pipeline de contenu où un « Chercheur » déterre des sources, un « Analyste » trouve des modèles, et un « Rédacteur » rédige l’article ? Là, la métaphore a du sens. CrewAI brille lorsque le problème ressemble réellement au travail d’équipe.
AutoGen
import os
from autogen import AssistantAgent, UserProxyAgent
llm_config = {
"model": "gpt-4",
"api_key": os.environ["OPENAI_API_KEY"]
}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
user_proxy.initiate_chat(assistant, message="Quelle est la météo à Tokyo ?")
Deux agents. Parlent entre eux. C’est tout le principe d’AutoGen — le modèle conversationnel. UserProxyAgent fait semblant d’être vous, AssistantAgent répond. Pour le brainstorming ou la révision de code, c’est un concept pratique.
Pour « juste obtenir la météo à Tokyo » ? C’est comme engager deux personnes pour avoir une réunion au sujet de l’application météo.
Aussi : le modèle dans leur exemple officiel est toujours gpt-4, pas gpt-4o. La documentation n’a pas été mise à jour. C’est un petit détail. Ce n’est pas non plus un petit détail.
Ce que Reddit Pense Réellement
Citations directes. Compte d’upvotes inclus pour que vous puissiez les évaluer vous-même.
La voix la plus forte dans la pièce dit : passez les cadres
D’un développeur qui a construit des agents pour plus de 20 entreprises (685 upvotes) :
« Ne commencez pas avec LangChain ou CrewAI ou quoi que ce soit qui soit à la mode cette semaine. Ils cachent trop de choses. Vous devez comprendre ce qui se passe sous le capot. Écrivez un script Python brut qui interroge l’API OpenAI ou Anthropic. Envoyez un message. Recevez une réponse. C’est tout. »
D’une personne qui construit des agents pour des clients depuis deux ans (378 upvotes) :
« Ceux qui font réellement de l’argent et ne cassent pas chaque semaine ? Ils sont embarrassamment simples. Un seul agent qui lit les e-mails et met à jour les champs CRM (200 $/mois, tourne 24/7). Un parseur de CV qui extrait des informations clés pour les recruteurs (50 $/mois). Aucun de ces agents n’a nécessité d’orchestration. Aucun besoin de systèmes de mémoire. Ils n’avaient certainement pas besoin d’équipes d’agents se réunissant pour décider quoi faire. »
Son stack de production : API OpenAI, n8n, un webhook, peut-être Supabase. C’est tout. Il gagne de l’argent. Le gars avec le système CrewAI à 47 agents fait des posts LinkedIn.
Le contrepoint à entendre
Un commentateur qui a réellement déployé un agent dans un hôpital (seulement 4 upvotes, mais lisez quand même) :
« J’ai récemment déployé un agent vocal IA dans un hôpital qui triage l’état des patients de manière mesurable plus précise que le personnel. Cela a nécessité beaucoup de réglages fins et un excellent prompt qui l’a formé sur la manière de faire le triage des patients, mais cela fonctionne très bien. »
Pas de mention de quel cadre. Parce que ça n’a pas d’importance. Il a passé son temps sur le prompt et le réglage fin, pas à choisir entre LangChain et CrewAI.
La chose que personne ne veut dire à voix haute
Le commentaire principal (75 upvotes) sur un post populaire « J’ai passé 8 mois à construire des agents IA » ?
« Merci. C’était vraiment bon ChatGPT. »
Deuxième commentaire (49 upvotes) : « Les posts écrits par Chat GPT sont partout, mais voici ce que j’ai appris. rien, parce que je n’y ai pas mis d’efforts. »
La moitié des « rapports d’expérience » sur les cadres d’agents IA sont eux-mêmes générés par IA. Nous sommes dans une salle aux miroirs. Gardez cela à l’esprit lorsque vous lisez des articles de comparaison. Y compris, potentiellement, celui-ci — bien que je préfère penser que les timestamps de l’API GitHub et les liens Reddit me donnent une certaine crédibilité.
La Partie Argent
| LangSmith | Plateforme CrewAI | AutoGen | |
|---|---|---|---|
| Gratuit | 5K traces/mois, 1 siège | 50 exécutions/mois | Aucune plateforme existante |
| Payé | 39 $/siège/mois | 25 $/mois (100 exécutions) | — |
| Entreprise | Personnalisé | Personnalisé | — |
| Pour quoi vous payez | Observabilité & débogage | Hébergement & orchestration | Votre propre temps |
Ces chiffres sont presque sans pertinence. Voici pourquoi.
Un système multi-agents où trois agents discutent d’un problème consomme 30-50K tokens par exécution. Avec les tarifs de GPT-4o (2,50 $/1M d’entrées, 10 $/1M de sorties), cela revient à 0,15-0,75 $ par exécution. Si on le fait 1 000 fois par mois : 150-750 $ de coûts d’API. Les 25 $ par mois de frais pour la plateforme CrewAI ne sont qu’une erreur d’arrondi à côté de ça.
Pendant ce temps, le bot email à 200 $/mois de ce gars sur Reddit ? Probablement 5-10 $/mois en appels API. Un seul agent, une seule invite, un seul appel d’outil. Les calculs sont brutaux pour les architectures multi-agents.
Le Diagramme de Flux
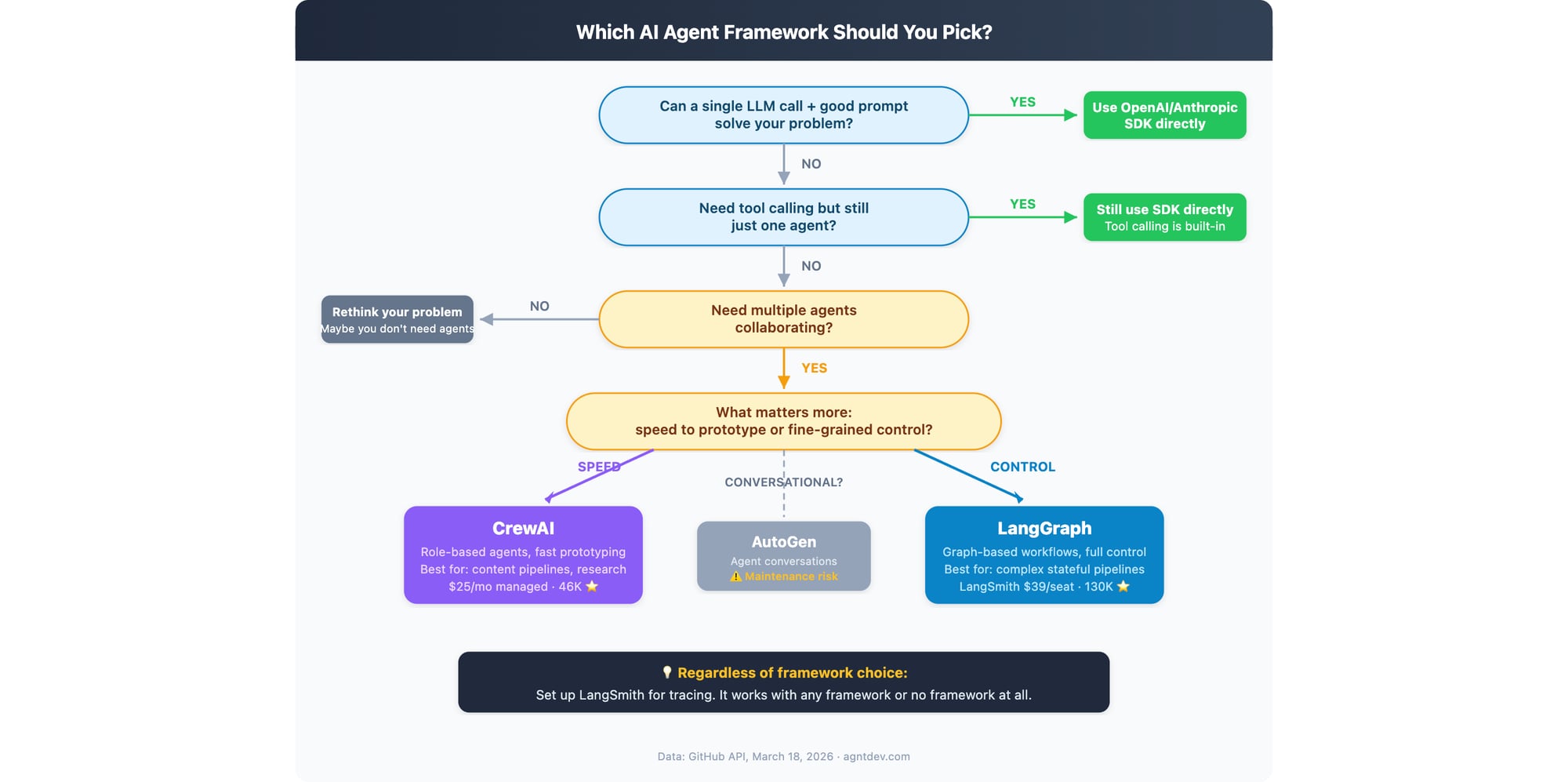
En mots, parce que tout le monde ne charge pas d’images :
Un appel LLM avec une bonne invite peut-il résoudre cela ? → Utilisez le SDK. Arrêtez-vous ici. La plupart des problèmes se trouvent ici et les gens ne veulent pas l’admettre.
Besoin d’appeler des outils mais un seul agent ? → Toujours le SDK. L’appel d’outil est maintenant natif à toutes les principales API LLM. Vous n’avez pas besoin d’un cadre pour appeler une fonction.
Vous avez vraiment besoin de plusieurs agents ? (Soyez honnête avec vous-même.)
→ Vous voulez une rapide mise en prototype : CrewAI
→ Vous voulez un contrôle total sur l’exécution : LangGraph
→ Vous voulez que les agents aient des conversations : AutoGen (mais relisez d’abord la section sur le risque de maintenance)
Besoin d’observabilité en production ? → LangSmith. Fonctionne avec tout, même sans cadre.
Ce que je ferais réellement
Ce que je ne recommanderais pas dans une présentation de conférence. Ce que je ferais réellement si je devais expédier quelque chose la semaine prochaine :
- Construire v1 avec des appels SDK bruts. Moche, manuel, sans abstractions. Faites-le fonctionner. Regardez-le échouer. Comprenez pourquoi cela échoue.
- Si un seul agent ne peut réellement pas gérer, prototypez la version multi-agent dans CrewAI. Cela prendra un après-midi.
- Si le prototype CrewAI fonctionne mais que j’ai besoin d’un contrôle plus précis pour la production, réécrivez les chemins critiques dans LangGraph. Gardez CrewAI pour les parties où « assez bon » est suffisant.
- LangSmith dès le premier jour. Non négociable. Voler à l’aveugle avec des agents en production, c’est comment vous recevez des appels à 3 heures du matin.
La étape 5 est celle que personne ne suit : n’ajoutez pas de complexité tant que la version simple ne casse pas en production. Pas en test. Pas dans votre tête. En production, avec de vrais utilisateurs, faisant de vraies choses. La plupart des gens n’arrivent jamais au-delà de l’étape 1 parce que l’étape 1 fonctionne réellement.
Le cadre représente 10 % du résultat. L’invite, les définitions d’outils, la gestion des erreurs, l’évaluation — c’est les autres 90 %. C’est là où le gars de l’hôpital a passé son temps. C’est là où le gars du bot email à 200 $/mois a passé son temps.
C’est là où vous devriez passer le vôtre.
Données : GitHub API (18 mars 2026), tarification LangSmith, tarification CrewAI. Discussions sur Reddit sur r/AI_Agents et r/LangChain. Mis à jour le 19 mars 2026.
Articles Connexes
- Maîtriser les Tests d’Agents : Un Tutoriel Pratique avec des Exemples
- Meilleurs Outils de Complétion de Code AI 2025 : Augmenter la Productivité des Développeurs
- Make vs Activepieces : Lequel pour les Petites Équipes
🕒 Published: