I pulled the GitHub API on March 18, 2026. Read through Reddit threads with a combined 1,500+ upvotes. Checked the pricing pages, the release histories, the commit graphs.
Not vibes. Data.
The Numbers
| LangChain | CrewAI | AutoGen | |
|---|---|---|---|
| GitHub Stars | 130,068 | 46,455 | 55,836 |
| Forks | 21,444 | 6,268 | 8,414 |
| Open Issues | 505 | 494 | 684 |
| License | MIT | MIT | CC-BY-4.0 |
| Latest Stable | Mar 17, 2026 | Mar 18, 2026 (v1.11.0) | Sep 30, 2025 (v0.7.5) |
| Commits (last 4 weeks) | 187 total | 3 RCs in 3 days | Near zero |
| Born | Oct 2022 | Oct 2023 | Aug 2023 |
Source: GitHub API, pulled March 18, 2026.
LangChain: 130K stars, 47 commits/week, three and a half years old and still accelerating. Say what you want about the DX — the team ships.
CrewAI: 46K stars in two and a half years. Three release candidates in three consecutive days before v1.11.0 went stable. Small team energy. Moving fast, probably breaking things, but at least they’re moving.
AutoGen: this is where it gets uncomfortable. Last stable release? September 2025. Six months of silence from a Microsoft-backed project. 684 open issues piling up. The v0.4 rewrite split the community into people using the old API and people trying to figure out the new one. Neither group seems happy.
Show Me the Code
Enough talking. Here’s the same task — a weather-checking agent — in each framework plus vanilla SDK. Judge for yourself.
Raw OpenAI SDK (no framework)
from openai import OpenAI
import json
client = OpenAI()
def get_weather(city: str) -> str:
return f"72°F and sunny in {city}" # your real API call here
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}]
messages = [{"role": "user", "content": "What's the weather in Tokyo?"}]
response = client.chat.completions.create(
model="gpt-4o", messages=messages, tools=tools
)
# Handle tool call
tool_call = response.choices[0].message.tool_calls[0]
result = get_weather(json.loads(tool_call.function.arguments)["city"])
messages.append(response.choices[0].message)
messages.append({"role": "tool", "content": result, "tool_call_id": tool_call.id})
final = client.chat.completions.create(model="gpt-4o", messages=messages)
print(final.choices[0].message.content)
25 lines. Zero magic. You see every message going in and coming out. When it breaks — and it will — you’ll know exactly where to look.
This is what that 685-upvote Reddit post was talking about when it said “build your first one raw.”
LangChain
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Get current weather for a city."""
return f"72°F and sunny in {city}"
agent = create_agent(
model="gpt-4o",
tools=[get_weather],
system_prompt="You are a helpful weather assistant."
)
response = agent.invoke("What's the weather in Tokyo?")
print(response)
Clean. Short. And completely opaque. What happens inside agent.invoke()? Tool calling loop, message formatting, retry logic, maybe some prompt templating. All handled for you. Wonderful — until 2 AM when your agent starts returning nonsense and you’re stepping through five abstraction layers trying to figure out which one ate your tool response.
LangChain’s real value isn’t the agent abstraction. It’s the 150+ integrations (every vector store, every LLM provider, every document loader you can think of) and LangSmith, which is genuinely the best agent debugging tool available right now. More on that later.
CrewAI
from crewai import Agent, Task, Crew
from crewai.tools import tool
@tool
def get_weather(city: str) -> str:
"""Get current weather for a city."""
return f"72°F and sunny in {city}"
weather_agent = Agent(
role="Weather Reporter",
goal="Provide accurate weather information",
backstory="You are a meteorologist who gives concise weather reports.",
tools=[get_weather]
)
task = Task(
description="What's the weather in Tokyo?",
expected_output="A brief weather report",
agent=weather_agent
)
crew = Crew(agents=[weather_agent], tasks=[task])
result = crew.kickoff()
print(result)
More lines, different vibe entirely. You’re not writing a script, you’re casting a movie. role, goal, backstory — the agent has a character arc before it’s even done anything.
For checking the weather? Ridiculous overkill. For a content pipeline where a “Researcher” digs up sources, an “Analyst” finds patterns, and a “Writer” drafts the piece? Now the metaphor earns its keep. CrewAI shines when the problem actually looks like teamwork.
AutoGen
import os
from autogen import AssistantAgent, UserProxyAgent
llm_config = {
"model": "gpt-4",
"api_key": os.environ["OPENAI_API_KEY"]
}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
user_proxy.initiate_chat(assistant, message="What's the weather in Tokyo?")
Two agents. Talking to each other. That’s AutoGen’s whole thing — the conversational pattern. UserProxyAgent pretends to be you, AssistantAgent responds. For brainstorming or code review, it’s a neat paradigm.
For “just get me the weather in Tokyo”? It’s like hiring two people to have a meeting about checking the weather app.
Also: the model in their official example is still gpt-4, not gpt-4o. Docs haven’t been updated. It’s a small thing. It’s also not a small thing.
What Reddit Actually Thinks
Direct quotes. Upvote counts included so you can weigh them yourself.
The loudest voice in the room says: skip the frameworks
From a developer who’s built agents for 20+ companies (685 upvotes):
“Do not start with LangChain or CrewAI or whatever is trending this week. They hide too much. You need to understand what is happening under the hood. Write a raw Python script that hits the OpenAI or Anthropic API. Send a message. Get a reply. That’s it.”
From someone who’s been building agents for clients for two years (378 upvotes):
“The ones that actually make money and don’t break every week? They’re embarrassingly simple. Single agent that reads emails and updates CRM fields ($200/month, runs 24/7). Resume parser that extracts key info for recruiters ($50/month). None of these needed agent orchestration. None needed memory systems. Definitely didn’t need crews of agents having meetings about what to do.”
His production stack: OpenAI API, n8n, a webhook, maybe Supabase. That’s it. He’s making money. The guy with the 47-agent CrewAI system is making LinkedIn posts.
The counterpoint worth hearing
A commenter who actually deployed an agent in a hospital (only 4 upvotes, but read it anyway):
“I deployed an AI voice agent in a hospital recently that triages patient status measurably more accurately than the staff does. It took a shitload of fine tuning and a really excellent system prompt that educated it on how to do patient triage, but it works great.”
No mention of which framework. Because it doesn’t matter. He spent his time on the prompt and the fine-tuning, not on picking between LangChain and CrewAI.
The thing nobody wants to say out loud
The top comment (75 upvotes) on a popular “I spent 8 months building AI agents” post?
“Thank you. This was really good ChatGPT.”
Second comment (49 upvotes): “Chat GPT written posts are everywhere, but here’s what I learned. nothing, because I didn’t put any effort in.”
Half the “experience reports” about AI agent frameworks are themselves AI-generated. We’re in a hall of mirrors. Keep that in mind when you’re reading comparison articles. Including, potentially, this one — though I’d like to think the GitHub API timestamps and Reddit links give me some credibility.
The Money Part
| LangSmith | CrewAI Platform | AutoGen | |
|---|---|---|---|
| Free | 5K traces/mo, 1 seat | 50 executions/mo | No platform exists |
| Paid | $39/seat/mo | $25/mo (100 executions) | — |
| Enterprise | Custom | Custom | — |
| What you’re paying for | Observability & debugging | Hosting & orchestration | Your own time |
These numbers are almost irrelevant. Here’s why.
A multi-agent setup where three agents discuss a problem burns 30-50K tokens per run. At GPT-4o pricing ($2.50/1M input, $10/1M output), that’s $0.15-0.75 per execution. Run it 1,000 times a month: $150-750 in API costs. The $25/month CrewAI platform fee is a rounding error next to that.
Meanwhile, that Reddit guy’s $200/month email bot? Probably $5-10/month in API calls. Single agent, single prompt, single tool call. The math is brutal for multi-agent architectures.
The Flowchart
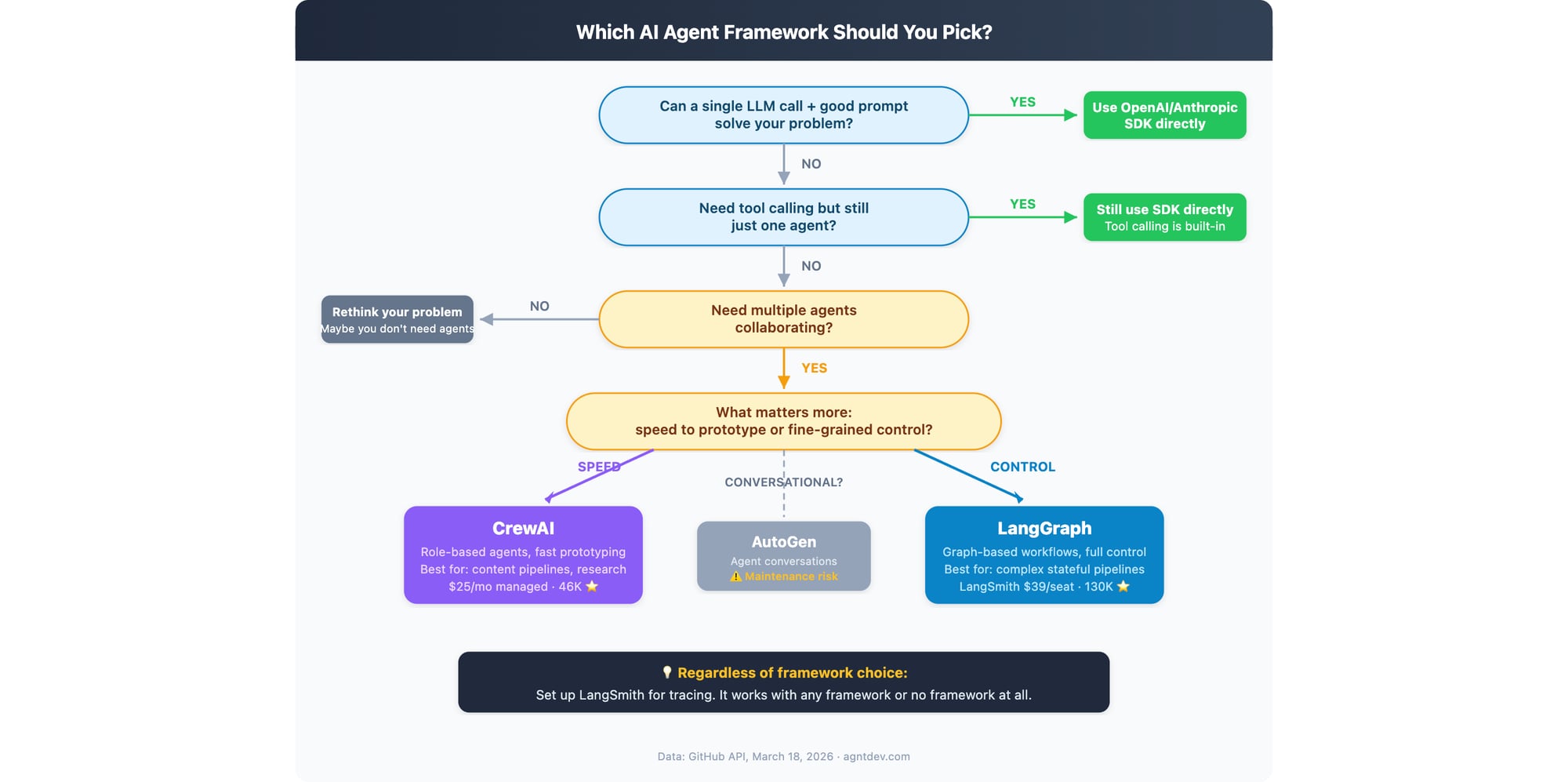
In words, because not everyone loads images:
Can one LLM call with a good prompt solve it? → Use the SDK. Stop here. Most problems live here and people don’t want to admit it.
Need tool calling but still one agent? → Still the SDK. Tool calling is native to every major LLM API now. You don’t need a framework to call a function.
Actually need multiple agents? (Be honest with yourself.)
→ Want speed to prototype: CrewAI
→ Want full control over execution: LangGraph
→ Want agents having conversations: AutoGen (but read the maintenance risk section again first)
Need production observability? → LangSmith. Works with everything, including no framework at all.
What I’d Actually Do
Not what I’d recommend in a conference talk. What I’d actually do if I had to ship something next week:
- Build v1 with raw SDK calls. Ugly, manual, no abstractions. Get it working. Watch it fail. Understand why it fails.
- If one agent genuinely can’t handle it, prototype the multi-agent version in CrewAI. It’ll take an afternoon.
- If the CrewAI prototype works but I need tighter control for production, rewrite the critical paths in LangGraph. Keep CrewAI for the parts where “good enough” is good enough.
- LangSmith from day one. Non-negotiable. Flying blind with agents in production is how you get 3 AM pages.
Step 5 is the one nobody follows: don’t add complexity until the simple version breaks in production. Not in testing. Not in your head. In production, with real users, doing real things. Most people never get past step 1 because step 1 actually works.
The framework is 10% of the outcome. The prompt, the tool definitions, the error handling, the evaluation — that’s the other 90%. That’s where the hospital guy spent his time. That’s where the $200/month email bot guy spent his time.
That’s where you should spend yours.
Data: GitHub API (March 18, 2026), LangSmith pricing, CrewAI pricing. Reddit threads on r/AI_Agents and r/LangChain. Updated March 19, 2026.
Related Articles
- Mastering Agent Testing: A Practical Tutorial with Examples
- Best AI Code Completion Tools 2025: Boosting Developer Productivity
- Make vs Activepieces: Which One for Small Teams
🕒 Published: